If you are feeling overwhelmed by the jargon—don’t worry. I’ve been there. In my 15 years working with AI learning methods and automation, I’ve learned that success isn’t about knowing the most complex math; it’s about choosing the right approach for the job.
Whether you are a developer, a business owner, or a student, understanding the machine learning basics is non-negotiable today. It is no longer just theory; it is the engine behind the Netflix recommendations you watch and the fraud detection protecting your bank account.
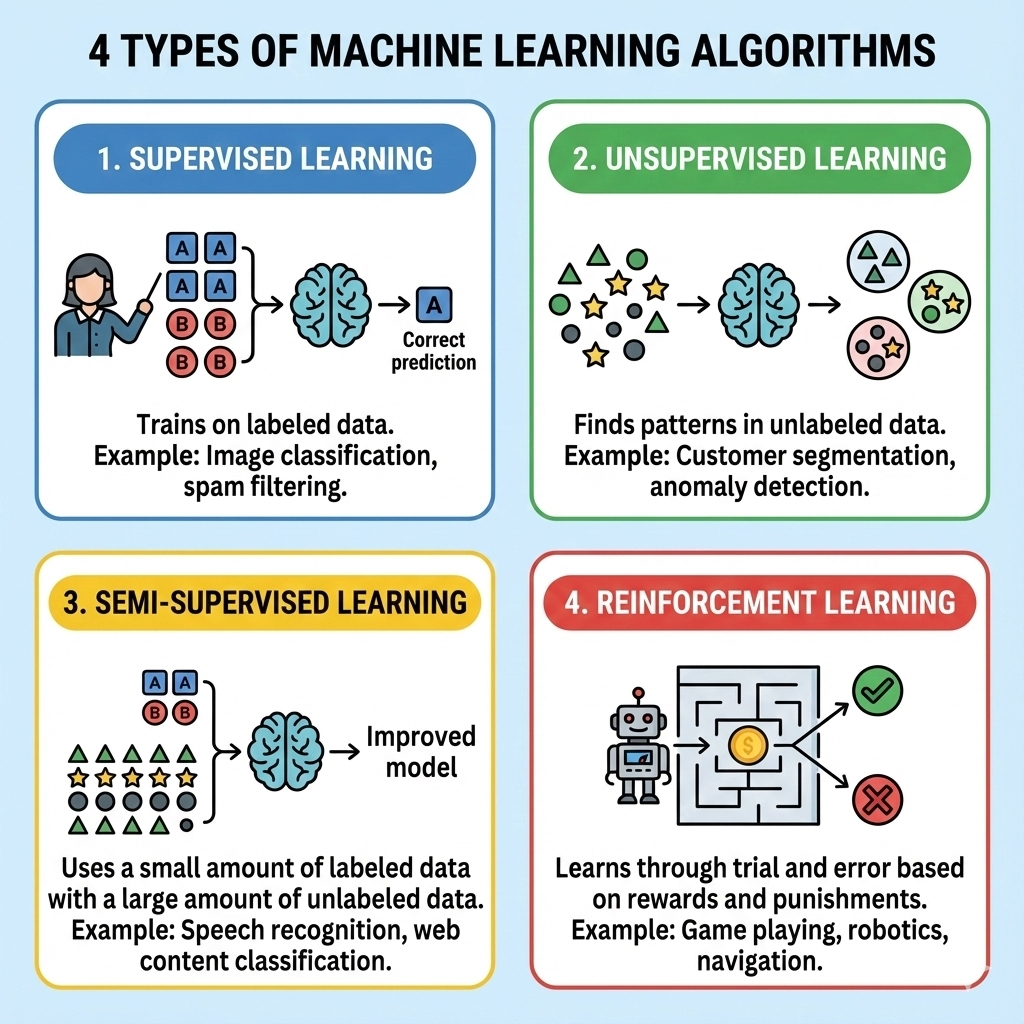
In this guide, I’m going to break down the four main machine learning algorithms and methodologies. I’ll strip away the academic fluff and give you the practical, “in-the-trenches” knowledge you need to distinguish supervised vs unsupervised learning and everything in between.
The Pain Point: Why Most Beginners Fail at ML
Here is the brutal truth: Most AI projects fail not because of bad code, but because of bad architecture. I see beginners trying to use Reinforcement Learning to classify simple emails, or trying to use Supervised Learning when they don’t have a budget for data labeling.
If you choose the wrong path, you will waste months. This article is your roadmap to avoiding those pitfalls. We are going to cover:
- Supervised Learning: The strict teacher.
- Unsupervised Learning: The explorer.
- Semi-Supervised Learning: The hybrid efficiency.
- Reinforcement Learning: The gamer.
Phase 1: Preparation – What You Need Before You Start
Before we dive into what are the 4 types of machine learning, let’s set up your environment. You can’t learn this just by reading; you need to get your hands dirty. Based on my experience, here is the leanest setup to get started:
- Compute Power: You don’t need a supercomputer yet. A standard laptop with 16GB RAM is fine for learning. For heavier lifting later, I recommend Google Colab (the free tier is excellent).
- The Stack: Python is the king here. Make sure you have Anaconda or a virtual environment set up with:
- Scikit-learn (for standard algorithms)
- TensorFlow or PyTorch (for deep learning)
- Pandas (for data manipulation)
- Data Mindset: You need patience. 80% of your time will be spent cleaning data, not modeling.
Phase 2: The 4 Types of Machine Learning Explained (Step-by-Step Implementation)
Let’s walk through these methods as if we are building a project together.
1. Supervised Learning: The “Teacher” Approach
This is the bread and butter of the industry. In Supervised Learning, we feed the machine data that is already “labeled.” Think of it like a teacher holding up a flashcard that says “Apple” and showing a picture of an apple.
How it works in the real world:
I once built a system for a logistics company to read handwritten addresses. We fed the model 100,000 images of handwriting (Input) paired with the actual text (Output/Label). The algorithm minimizes the error between its guess and the actual label.
Pros:
- High Accuracy: Since we know the “truth,” we can measure success precisely using metrics like Accuracy or F1-score.
- Easy to Interpret: We know exactly what the model is trying to achieve.
Cons (The Catch):
- The Labeling Bottleneck: This is expensive. Humans have to manually label that data. I’ve seen projects stall because nobody wanted to sit and tag 50,000 images.
- Rigidity: If you train it to recognize cats, it will have no idea what a dog is. It cannot improvise.
Top Machine Learning Examples for Beginners: spam filtering, house price prediction, face recognition.
Pro Tip: Don’t just rely on “Accuracy.” If you are building a fraud detector where only 1% of transactions are fraud, a model that says “Not Fraud” every time is 99% accurate but completely useless. Use “Recall” and “Precision” instead.
2. Unsupervised Learning: The “Discovery” Approach
Now, imagine you dump a pile of documents on a desk and say, “I don’t know what these are. You sort them.” That is Unsupervised Learning. There are no labels. The AI must find patterns, structures, or anomalies on its own.
I often use this when a client hands me messy data and asks, “What does our customer base look like?”
Core Mechanisms:
- Clustering: Grouping similar data points (e.g., “These customers all buy diapers and beer”).
- Dimensionality Reduction: Simplifying complex data so humans can visualize it.
Pros:
- No Labeling Required: This saves massive amounts of time and money.
- Hidden Insights: It finds patterns humans might miss because we weren’t looking for them.
Cons:
- Unpredictable Results: Sometimes the AI finds patterns that are mathematically correct but business-nonsense.
- Hard to Validate: Since there is no “correct answer,” it’s hard to tell if the model is doing a good job.
3. Semi-Supervised Learning: The “Hybrid” Approach
This is one of the most practical ML techniques for businesses today. It sits right between supervised vs unsupervised learning. You take a small amount of labeled data and mix it with a huge amount of unlabeled data.
Real-world Scenario:
I worked on a medical imaging project. We had thousands of X-rays, but only a few dozen had been diagnosed by doctors (because doctors are expensive!). We used the few diagnosed images to guide the model, and it then used the structure of the thousands of undiagnosed images to refine its understanding.
Pros:
- Cost-Effective: drastic reduction in labeling costs.
- Improved Accuracy: Often performs better than supervised learning if labeled data is scarce.
Cons:
- Complexity: It is harder to implement. If the unlabeled data is “noisy” (full of garbage), it can actually confuse the model and make it worse than if you just used the small labeled set.
4. Reinforcement Learning: The “Trial and Error” Approach
This is the most exciting and complex type. In Reinforcement Learning (RL), an agent learns by interacting with an environment. It tries something, gets a reward (points, score) or a penalty (game over), and adjusts its strategy.
Think of training a dog. You don’t explain English to the dog; you give it a treat when it sits and ignore it when it jumps. The dog learns to maximize the treats.
Applications:
- Robotics: Teaching a robot arm to grasp an object.
- Game Playing: This is how AlphaGo beat the world champion.
- Resource Management: Optimizing cooling in data centers.
Pros:
- Solves Complex Problems: Can figure out strategies that humans never thought of.
- Adaptable: It learns continuously as the environment changes.
Cons:
- Computationally Expensive: It requires millions of simulations.
- Safety Risks: An RL agent might find a “cheat” to maximize points that is dangerous in the real world (like a self-driving car speeding to reach a destination faster).
Common Troubleshooting & Expert Advice
In my consulting work, I see the same issues crop up repeatedly when teams try to implement these types of machine learning.
1. Overfitting (The Memorization Trap)
This happens in Supervised Learning when your model memorizes the training data instead of learning the rules. It gets 100% on the test but fails in the real world.
Fix: Use techniques like “Cross-Validation” and “Regularization.” Stop training before the error rate on validation data starts to rise.
2. Garbage In, Garbage Out
If your dataset is biased, your AI will be biased. I once saw a hiring bot that rejected all female candidates because it was trained on historical data from a male-dominated industry.
Fix: Spend more time auditing your data than tuning your machine learning algorithms.
3. The Black Box Problem
With Deep Learning (a subset of ML), it is often hard to explain why the model made a decision. In finance and healthcare, this is a dealbreaker.
Fix: For critical sectors, consider using simpler models like Decision Trees or Linear Regression first, which are interpretable.
Conclusion: Which Method Should You Choose?
Understanding what are the 4 types of machine learning is just the first step. The magic happens when you apply them to the right problem.
- Choose Supervised Learning if you have plenty of historical data and know exactly what you want to predict (e.g., sales forecasting).
- Choose Unsupervised Learning if you have data but no clear goal other than “exploration” (e.g., customer segmentation).
- Choose Semi-Supervised Learning if data is cheap but labeling is expensive (e.g., medical analysis).
- Choose Reinforcement Learning if you are building a system that needs to make a sequence of decisions in a dynamic environment (e.g., robotics).
My advice? Start small. Pick a simple Supervised Learning problem, clean your data, and get a model running. The world of AI is vast, but it rewards action over theory.
Ready to start? Open up your Python editor and import Scikit-learn today. The best way to learn is to code.
Frequently Asked Questions
What is the most common type of machine learning?
Supervised Learning is currently the most widely used method in business applications because it provides specific, measurable results for problems like classification and regression.
Can a system use multiple types of machine learning?
Absolutely. For example, a system might use Unsupervised Learning to cluster users and then use Supervised Learning to recommend products to those specific clusters. This is often called an ensemble or hybrid approach.
Is Reinforcement Learning the future of AI?
It is a significant part of the future, particularly for robotics and autonomous vehicles (AGI). However, for standard business analytics, Supervised and Unsupervised learning will remain dominant for a long time due to their efficiency and lower cost.